今天我們終於來到了文字翻譯技術的總結了,這次的內容會非常複雜,你可以將其想像為我們從第1天到第10天學習到的知識的綜合體,所以在今天我將把這些程式碼進行拆解,讓你理解Pytorch中該怎麼使用公式來實現Seq2Seq+Attention的架構,今天的學習內容如下:
今日我們將透過Pytorch實現文字翻譯的技術,而這次選擇的語言對象是英語和法語。至於為何選擇英語和法語呢?這是因為英語和法語是全球使用範圍最廣的語言之一,所以已經有大量的線上及書面資源,並且英語和法語同為印歐語系,因此許多詞彙在某些層面上非常相似,所以選擇它們作為訓練的目標語言更為合適。
首先我們需要先前往Pytorch官網下載今天將要使用的資料集,當然你可以用自己想要翻譯的語言集,但是在資料整理的步驟你就需要進行改良或參考以下的輸入格式。
在此資料集中的英語和法語儲存方式是透過一個txt檔案進行的,該資料集內容上,左側是英文,右側則是法語,其內容如下所示:
Go. Va !
Run! Cours !
Run! Courez !
Wow! Ça alors !
Fire! Au feu !
Help! À l'aide !
Jump. Saute.
我們所需要做的就是利用Python讀取該txt的內容,並建立英文與法語的標記器,確保能夠正常進行轉換。
在該步驟中我們應該不會太陌生,因為我們在【Day 8】文字也是一種有時間序列的資料(下)-用IMDB影評探索文字中的情緒的學習過程中,我們就已經使用過這種方式了。但是這裡有些細節和會語之前不相同。
之前我們在TorchText中的get_tokenizer()的可以直接使用basic_english的方式呼叫標記器,但對於其他語言,我們必須採用其他函式庫的檔案,因此我們需要先安裝spacy的法語的資料包,可以透過以下指令進行安裝:
!pip install spacy
!python -m spacy download fr_core_news_sm
當安裝完畢後我們還需要建立兩個不同的標記器,已分別針對英語和法語斷詞的動作。
from torchtext.data.utils import get_tokenizer
# 建立標記器
french_tokenizer = get_tokenizer('spacy', language='fr_core_news_sm')
englisg_tokenizer = get_tokenizer('basic_english')
接下來我們將撰寫一個函數,此函數需要回傳每句話中詞彙的出現次數,但在此之前,我們需要先利用Python的open()函數讀取我們的資料集。
with open('data/eng-fra.txt', 'r',encoding='utf-8') as f:
text_datas = f.readlines()
在上述程式中,我們是利用readlines()讀取整份文件的資料,但該方式會在每行結尾預設一個\n作為換行符,並且該資料集的內容是以TAB鍵作分隔英語和法語,故會產生\t符號,因此每筆資料在程式中的結果如下所示。
[
Go.\tVa !\n,
Run!\tCours !,
\nRun!\tCourez !\n,
...
]
因此該函數的計算方式可以寫成下方這種格式,使其能夠幫助我們快速的統計出最終結果,並將被斷詞的詞彙回傳給主程式以方便後續的使用。
from collections import Counter
def preprocessing(french_tokenizer, englisg_tokenizer):
en_counter, fr_counter = Counter(), Counter()
english, french = [], []
for text_data in text_datas:
en, fr = text_data.strip('\n').split('\t')
en_tokens, fr_tokens = englisg_tokenizer(en), french_tokenizer(fr)
english.append(en_tokens)
french.append(fr_tokens)
en_counter.update(en_tokens)
fr_counter.update(fr_tokens)
return en_counter, fr_counter, english, french
en_counter, fr_counter, english, french = preprocessing(french_tokenizer, englisg_tokenizer)
在上述程式中,我們的主要處理步驟是先使用strip()來刪除文字前後的\n,然後再利用\t來分割文字。這樣我們將會得到一個包含兩個元素的串列資料,分別是英語和法語。
同時我們還可以取出相應的字串,並利用各自的斷詞器進行斷詞操作,使其能通過Counter()統計每個詞彙出現的次數。
這次建立詞彙表的方式也是通過vocab()來處理,但在這裡要特別注意,我們這次需要加入4個特殊的詞彙標籤:<PAD>、 <SOS>、<EOS>、<UNK>,其中<SOS>和<EOS>是需要添加到每句話的開頭和結尾的特殊標籤,其目的是為了提醒模型知道何時該結束。
from torchtext.vocab import vocab
# 建立詞彙表
en_vocab = vocab(en_counter, min_freq=5, specials=('<PAD>', '<SOS>','<EOS>','<UNK>'))
en_vocab.set_default_index(en_vocab.get_stoi()['<UNK>'])
fr_vocab = vocab(fr_counter, min_freq=5, specials=('<PAD>', '<SOS>','<EOS>','<UNK>'))
fr_vocab.set_default_index(en_vocab.get_stoi()['<UNK>'])
接下來我們需要取得詞嵌入層的大小以及一些特定的索引值,以便後續直接使用這些索引進行超參數的設定。
# Ecoder與Decoder的Embedding輸入大小
INPUT_DIM = len(en_vocab)
OUTPUT_DIM = len(fr_vocab)
# 取得給予模型的索引值
SOS_IDX = en_vocab.get_stoi()['<SOS>']
EOS_IDX = en_vocab.get_stoi()['<EOS>']
PAD_IDX = en_vocab.get_stoi()['<PAD>']
在資料前處理的步驟中,我們需要在英語和法語文本的尾端加上結束標記<EOS>,並且還需要確保每一批次的文本長度相同,因此我們必須在程式中將這兩種語言的文本維度統一。
from torch.nn.utils.rnn import pad_sequence
english_num, french_num = [], []
for i in range(len(english)):
en_num = en_vocab.lookup_indices(english[i]) + [EOS_IDX]
fr_num = fr_vocab.lookup_indices(french[i]) + [EOS_IDX]
english_num.append(torch.tensor(en_num))
french_num.append(torch.tensor(fr_num))
all_seq = english_num + french_num
pad_seq = pad_sequence(all_seq, padding_value=PAD_IDX, batch_first=True)
在這裡,為了方便處理我先將兩者文本進行相加,接下來我使用pad_sequence()使所有長度能夠統一,這一步在之前的情緒分析訓練時,我們是把它放入collate_fn()中處理。
但上次我們這樣處理,主要是因為文章長短相差過大,所以以最長的序列作為填充時就會導致訓練時間過長,但這次序列的差距並不大,所以我選擇在一開始就進行填充,如此一來,在訓練過程中不需要轉換資料,進而加快模型訓練的速度。
english_num, french_num = pad_seq[:len(english_num)], pad_seq[len(english_num):]
MAX_LEN = len(english_num[0])
x_train, x_valid, y_train, y_valid = train_test_split(english_num, french_num, train_size=0.8, random_state=46, shuffle=False)
接下來我們在處理完填充資料後還需要將其分割回來,在這裡我直接使用了英語資料的長度作為索引進行分割,當分割完畢後,還需要計算出每一個序列的長度,這是因為在Decoder產生的文字需要與我們的目標文字等長才能計算損失。當我們都執行完畢後就能夠將資料切分成訓練集與驗證集,並將其包裝為Dataset後接著交由Dataloader處理。
class TranslateDataset(Dataset):
def __init__(self, x, y):
self.x = x
self.y = y
def __getitem__(self, index):
return self.x[index], self.y[index]
def __len__(self):
return len(self.x)
trainset = TranslateDataset(x_train, y_train)
validset = TranslateDataset(x_valid, y_valid)
train_loader = DataLoader(trainset, batch_size = 1024, shuffle = True, num_workers = 0, pin_memory = True)
valid_loader = DataLoader(validset, batch_size = 1024, shuffle = True, num_workers = 0, pin_memory = True)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
這次的計算量相對較大,因此我選擇使用GRU作為時間序列模型,其模型的堆疊方式與先前情緒分析是一樣的,但在這裡,我們需要獲取完整的輸出狀態和隱藏狀態,因為這些狀態將會是注意力機制和Decoder的輸入資料。
import torch.nn as nn
class EncoderRNN(nn.Module):
def __init__(self, input_size, hidden_size, dropout_p=0.1):
super(EncoderRNN, self).__init__()
self.hidden_size = hidden_size
self.embedding = nn.Embedding(input_size, hidden_size, padding_idx=PAD_IDX)
self.gru = nn.GRU(hidden_size, hidden_size, batch_first=True)
self.dropout = nn.Dropout(dropout_p)
def forward(self, input):
embedded = self.dropout(self.embedding(input))
output, hidden = self.gru(embedded)
return output, hidden
encoder = EncoderRNN(input_size = INPUT_DIM, hidden_size = 128).to(device)
這個步驟是我們在昨天的教學【Day 10】掌握文字翻譯的技術(中)-為何需要注意力機制注意力機制的程式碼,我們可以先看到以下程式:
import torch.nn.functional as F
class BahdanauAttention(nn.Module):
def __init__(self, hidden_size):
super(BahdanauAttention, self).__init__()
self.Wa = nn.Linear(hidden_size, hidden_size)
self.Ua = nn.Linear(hidden_size, hidden_size)
self.Va = nn.Linear(hidden_size, 1)
在初始化注意力機制的過程中,其實是透過一系列Linear()進行計算的,你可能會想到Linear()不就是深度神經網路的部分嗎?在這裡我們可以回憶一下【Day 7】文字也是一種有時間序列的資料(上)-時間序列模型大揭密這篇文章的內容。
我們曾提到在LSTM等模型的公式中,將會分為x(t)和h(t)兩部分,這兩個部分會分別與其對應的權重進行乘法運算,然後再加總後透過tanh函數進行計算其資料分布。在這個過程中,某個輸入與其權重的乘法運算實際上就是深度神經網路的計算原理。
因此針對Decoder的注意力機制來說,公式主要是將hd(t)和h(t)這兩部分的數據進行運算,並將結果的前向傳播計算,其實際方式可以看下方的程式碼(下方程式有公式代號可供參考)。
def forward(self, query, keys):
# v * tanh(query(hd) * w + keys(h) * w) Score的其中一種計算方式(可自行修改)
# 注意力分數的計算方式
scores = self.Va(torch.tanh(self.Wa(query) + self.Ua(keys))) # a(t)
scores = scores.squeeze(2).unsqueeze(1)
# 注意力權重的計算方式
weights = F.softmax(scores, dim=-1) # a'(t)
# 兩個矩陣後兩個維度需相同大小
context = torch.bmm(weights, keys) # c(t)
return context, weights
在以上的程式中,我們首先計算出注意力分數,並利用softmax()將其轉換為注意力權重,但在後續計算c(t)時你可能會發現,似乎沒有計算每個隱狀態之間的結果的這一個步驟。
這正是我要說明的bmm()計算方式的用途,這種方式類似於矩陣相乘的動作,但不會進行加總,因此在過程中每一個元素都會被完整計算,所以我們可以用這種方法快速計算每個隱狀態之間的結果。
我們終於進行到今天最複雜的部分Decoder了,要開始這個步驟錢,因為需要將先前所完成的每一個動作都放在Decoder中,因此前向傳播時我們還需處理許多細節,首先我們來看看初始化的部分。
class AttnDecoderRNN(nn.Module):
def __init__(self, hidden_size, output_size, dropout_p=0.1):
super(AttnDecoderRNN, self).__init__()
self.embedding = nn.Embedding(output_size, hidden_size, padding_idx=PAD_IDX)
self.attention = BahdanauAttention(hidden_size)
self.gru = nn.GRU(2 * hidden_size, hidden_size, batch_first=True)
self.out = nn.Linear(hidden_size, output_size)
self.dropout = nn.Dropout(dropout_p)
在這部分,我們只是將先前的注意力機制層引入到解碼器層中。然而,前向傳播方式較為複雜,所以接下來我將把程式碼仔細拆解,以讓你更清楚這程式的具體意義。
首先我們需要創建一個與當前批次大小相等的<SOS>標籤,該標籤是Decoder的第一個輸入資料,使其能夠進行推理的動作,接下來我們也需建立decoder_outputs這個串列,用以儲存每次生成的文字,讓其能被損失函數所使用,attentions則是可視化注意力機制時所用到的結果。
def forward(self, encoder_outputs, encoder_hidden, target_tensor=None):
batch_size = encoder_outputs.size(0)
decoder_input = torch.empty(batch_size, 1, dtype=torch.long, device=device).fill_(SOS_IDX)
decoder_hidden = encoder_hidden
decoder_outputs = []
attentions = []
另外在Decoder的部分由於需要考慮到Encoder的隱狀態h(t)與decoder的隱狀態hd(t),以及為了滿足注意力機制的需求,所以我們必須考量Encoder中的所有隱狀態encoder_outputs。
為此我需要新增一個forward_step()方法,該方法的目的是讓這些參數可以給注意力機制進行運算來定位最適合的上下文向量c(t),並將這個上下文向量c(t)與Decoder的輸入<SOS>...<EOS>透過cat()函數結合之後,再提供給GRU進行運算,來計算出文字的生成結果。
def forward_step(self, input, hidden, encoder_outputs):
embedded = self.dropout(self.embedding(input))
query = hidden.permute(1, 0, 2)
context, attn_weights = self.attention(query, encoder_outputs)
input_gru = torch.cat((embedded, context), dim=2)
output, hidden = self.gru(input_gru, hidden)
output = self.out(output)
return output, hidden, attn_weights
當完成上述步驟後,我們就能透過迴圈不斷生成文字,直至達到設定的最大值,在這裡我所採用的訓練策略是Teacher forcing,也就是透過將實際標籤給予Decoder生成,因為此方法能有效加快收斂速度。
for i in range(MAX_LEN):
decoder_output, decoder_hidden, attn_weights = self.forward_step(
decoder_input, decoder_hidden, encoder_outputs
)
decoder_outputs.append(decoder_output)
attentions.append(attn_weights)
if target_tensor is not None:
# Teacher forcing
decoder_input = target_tensor[:, i].unsqueeze(1) # Teacher forcing
else:
# 不使用Teacher forcing(不給予標籤進行訓練)
_, topi = decoder_output.topk(1)
decoder_input = topi.squeeze(-1).detach() # detach from history as input
decoder_outputs = torch.cat(decoder_outputs, dim=1)
# 計算文字機率
decoder_outputs = F.log_softmax(decoder_outputs, dim=-1)
attentions = torch.cat(attentions, dim=1)
return decoder_outputs, decoder_hidden, attentions
decoder = AttnDecoderRNN(hidden_size = 128, output_size = OUTPUT_DIM).to(device)
小提示:
在這個階段因為我一步步地分解並說明程式碼,可能會導致你不知道實際的排版狀快,所以我建議你可以到我的GitHub上對照這些程式碼的位置,避免在邏輯上產生混淆。
訓練模型的方式與先前相同,然而這次我們有兩個模型,因此需宣告兩個優化器,而這次我們使用的是 NLLLoss(),這是一種多分類的損失函數,它與CrossEntropyLoss()相似,但不同之處在於CrossEntropyLoss() 是用 softmax 來計算機率,而NLLLoss()是使用 log softmax(softmax 的結果再取對數)。
import torch.optim as optim
encoder_optimizer = optim.Adam(encoder.parameters(), lr=1e-3)
decoder_optimizer = optim.Adam(decoder.parameters(), lr=1e-3)
criterion = nn.NLLLoss()
模型訓練的方式與先前相同,差異在於這次有兩個模型,因此在這部分我們需要分別調整兩個模型的權重,並且需要將Encoder所產生的最後一個狀態h(t)與完整的h(0)~h(t)給予Decoder進行生成,並且在損失函式計算時將所有維度攤平,使其能夠符合NLLLoss()的計算方式。
def train(epoch):
train_loss = 0
train_pbar = tqdm(train_loader, position=0, leave=True)
encoder.train()
decoder.train()
for input_datas in train_pbar:
inputs, targets = [i.to(device) for i in input_datas]
encoder_optimizer.zero_grad()
decoder_optimizer.zero_grad()
encoder_outputs, encoder_hidden = encoder(inputs)
decoder_outputs, _, _ = decoder(encoder_outputs, encoder_hidden, targets)
loss = criterion(
decoder_outputs.view(-1, decoder_outputs.size(-1)),
targets.view(-1)
)
loss.backward()
encoder_optimizer.step()
decoder_optimizer.step()
train_pbar.set_description(f'Train Epoch {epoch}')
train_pbar.set_postfix({'loss':f'{loss:.3f}'})
train_loss += loss.item()
return train_loss/len(train_loader)
同樣地對於驗證的方式,我們只需將全部有關梯度的部分移除即可,其他部分皆與訓練相同。
def valid(epoch):
valid_loss = 0
valid_pbar = tqdm(valid_loader, position=0, leave=True)
encoder.eval()
decoder.eval()
with torch.no_grad():
for input_datas in valid_pbar:
inputs, targets = [i.to(device) for i in input_datas]
encoder_outputs, encoder_hidden = encoder(inputs)
decoder_outputs, _, _ = decoder(encoder_outputs, encoder_hidden, targets)
loss = criterion(
decoder_outputs.view(-1, decoder_outputs.size(-1)),
targets.view(-1)
)
valid_pbar.set_description(f'Valid Epoch {epoch}')
valid_pbar.set_postfix({'loss':f'{loss:.3f}'})
valid_loss += loss.item()
return valid_loss/len(valid_loader)
接下來我們將進行100次的模型訓練並評估模型,此部分基本上不會有太大的修改空間,因為這就是訓練模型時所使用到的策略,所以在下方的程式碼中,你將看到與我們情緒辨識時的程式碼非常相似。
epochs = 100 # 訓練次數
early_stopping = 10 # 模型訓練幾次沒進步就停止
stop_cnt = 0 # 計數模型是否有進步的計數器
model_path = 'model.ckpt' # 模型存放路徑
show_loss = True # 是否顯示訓練折線圖
best_loss = float('inf') # 最佳的Loss
loss_record = {'train':[], 'valid':[]} # 訓練紀錄
for epoch in range(epochs):
train_loss = train(epoch)
valid_loss = valid(epoch)
loss_record['train'].append(train_loss)
loss_record['valid'].append(valid_loss)
# 儲存最佳的模型權重
if valid_loss < best_loss:
best_loss = valid_loss
torch.save(encoder.state_dict(), 'e' + model_path)
torch.save(decoder.state_dict(), 'd' + model_path)
print(f'Saving Model With Loss {best_loss:.5f}')
stop_cnt = 0
else:
stop_cnt+=1
# Early stopping
if stop_cnt == early_stopping:
output = "Model can't improve, stop training"
print('-' * (len(output)+2))
print(f'|{output}|')
print('-' * (len(output)+2))
break
print(f'Train Loss: {train_loss:.5f}' , end='| ')
print(f'Valid Loss: {valid_loss:.5f}' , end='| ')
print(f'Best Loss: {best_loss:.5f}', end='\n\n')
if show_loss:
show_training_loss(loss_record)
這次的訓練量可能會較大,因此可能需要稍待一些時間,不過程式順利完成執行後,我們就能看到以下的結果。
Train Epoch 87: 100%|████████████████████████████████████████████████████| 107/107 [00:25<00:00, 4.18it/s, loss=0.087]
Valid Epoch 87: 100%|██████████████████████████████████████████████████████| 27/27 [00:03<00:00, 8.95it/s, loss=0.570]
Train Loss: 0.08440| Valid Loss: 0.55161| Best Loss: 0.54151
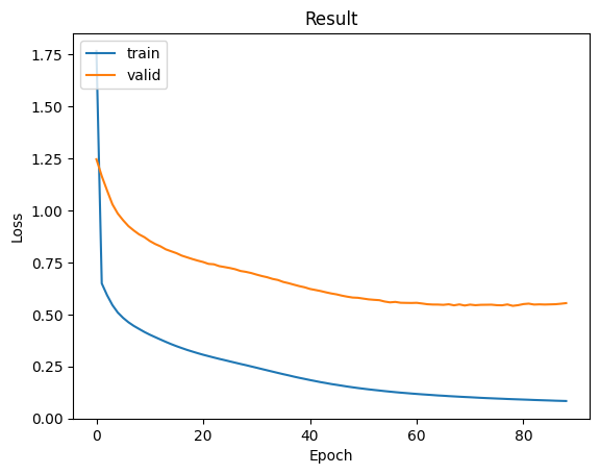
我們可以看到,當該模型訓練進入後期階段時,曲線會微微上升,在這裡其時就有過擬合的現象了,而我們所設定的訓練模式是只要連續10次loss值沒有改變,那麼模型就會停止訓練,這樣一來就能夠省下後續Epoch的時間。
但在這裡我們能發現一個問題,就是訓練資料的Loss值與驗證資料相比,訓練的Loss值低很多,這個情況主要是由於我們的資料集範圍不夠廣泛,因此在驗證時模型經常無法預測到資料裡的文字,而這種改善的方式就需要輸入更多的歷史資料,使訓練和驗證的Loss值達到平衡。
當模型訓練完成後,我們將採用貪婪解碼的方式生成文字,使用方法相當簡單,首先透過x_valid取得驗證集的資料(或是自行輸入一段文字),然後提升其維度並傳給Encoder進行解析,然後將其狀態給予Deocder進行解析。當程式生成完畢後我們每次將選取這些文字分布中機率最高的topk文字,並持續的迭代直到遇到<EOS>為止。
input_tensor = x_valid[0].to(device)
with torch.no_grad():
encoder_outputs, encoder_hidden = encoder(input_tensor.unsqueeze(0))
decoder_outputs, decoder_hidden, decoder_attn = decoder(encoder_outputs, encoder_hidden)
_, topi = decoder_outputs.topk(1)
decoded_ids = topi.squeeze()
decoded_words = []
for idx in decoded_ids:
if idx.item() == EOS_IDX:
break
decoded_words.append(idx.detach().cpu().tolist())
encoder_text = " ".join([en_vocab.lookup_token(i) for i in input_tensor if i!= PAD_IDX])
decoder_text = " ".join([fr_vocab.lookup_token(i) for i in decoded_words])
print("EN:", encoder_text)
print("FR:", decoder_text)
我們可以看到以下模型的輸出結果,該結果表明了我們的模型在文字理解上已有不錯的效果,如果我們增加更多的資料量,那麼在文字翻譯的任務上就會表現得更好。
EN: she went shopping with him last monday . <EOS> # 上週一她和他一起去購物
FR: Elle est allée faire les courses avec lui , au soir . # 晚上她和他一起去購物
在今天的最後一步,我將教你們如何將注意力機制作可視化。還記得我們在Decoder中所儲存的注意力權重嗎? 其實,我們存放這些數據的目的,就是為了現在的這一步。
在這裡所需做的動作相當簡單,因注意力權重是一個經過softmax的分數,所以只需將給予Encoder的序列資料與Decoder的序列資料進行比對,至於<PAD>標籤的部分我們忽略即可。而我們的注意力權重目前會是一個[1, 64, 64]的向量,然而我們的Encoder的向量只有[12],Decoder的向量只有9,因此我們需要將注意力權重轉變為[12, 12](第一個12對應Encoder,第二個對應Decoder),使其能夠忽略掉不重要的訊息。
import matplotlib.ticker as ticker
def showAttention(input_sentence, output_words, attentions):
fig = plt.figure()
ax = fig.add_subplot(111)
cax = ax.matshow(attentions.cpu().numpy(), cmap='bone')
fig.colorbar(cax)
# Set up axes
ax.set_xticklabels([''] + input_sentence.split(' '), rotation=90)
ax.set_yticklabels([''] + output_words.split(' '))
# Show label at every tick
ax.xaxis.set_major_locator(ticker.MultipleLocator(1))
ax.yaxis.set_major_locator(ticker.MultipleLocator(1))
plt.show()
showAttention(encoder_text, decoder_text, decoder_attn[0,:len(decoded_words),:len(decoded_words)])
當我們完成上述程式後,可以看到生成出來的法語文字所對應的英文單字,其詞彙意思與基本位置皆相同,而Decoder中不需要生成向量的部分顏色則接近於0。
且這張圖片中,我們可以得知是哪些字的隱狀態讓模型獲得一個較佳的效果,所以我們還可以根據這些結果來調整模型的訓練方式。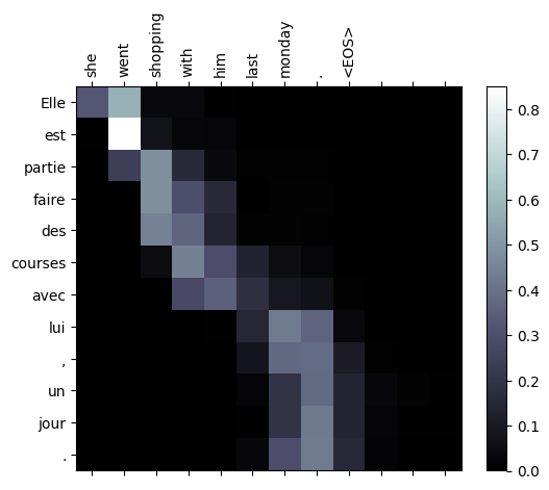
經過前幾日的理論學習與今天的程式的一連串砲轟之下,我想你可能會覺得快累死了。因此,明天我不再為你加碼難題,而是將這11天以來我提到名詞但未解釋知識,全部在明天補充給你,這些知識不會太過複雜。例如:損失函數和激勵函數的講解、以及中文的斷詞方式等,這些我都會從明天開始慢慢補充。
那麼我們明天再見!
內容中的程式碼都能從我的GitHub上取得:
https://github.com/AUSTIN2526/iThome2023-learn-NLP-in-30-days

